
以前、VBAで楽天の検索結果をエクセルに取り込む方法をメモしましたが、IE(Internet Explorer)を使用することが前提でした。しかし2020年にIEのサポートが終了。
実質この方法ではスクレイピングができなくなりました、、。
そこで、今話題のChatGPTにIEを使わないでスクレイピングする方法を聞いてみました!
前回のコードを参考に、IEを使用しない方法で書き直します。
取り込むデータの確認
うちのにゃんこは今年で20歳になりましたが、まだまだ元気です!
今回も猫フードの検索結果をExcelに取り込みたいと思います。
キーワードは「猫 餌 20歳」です。
楽天の検索結果
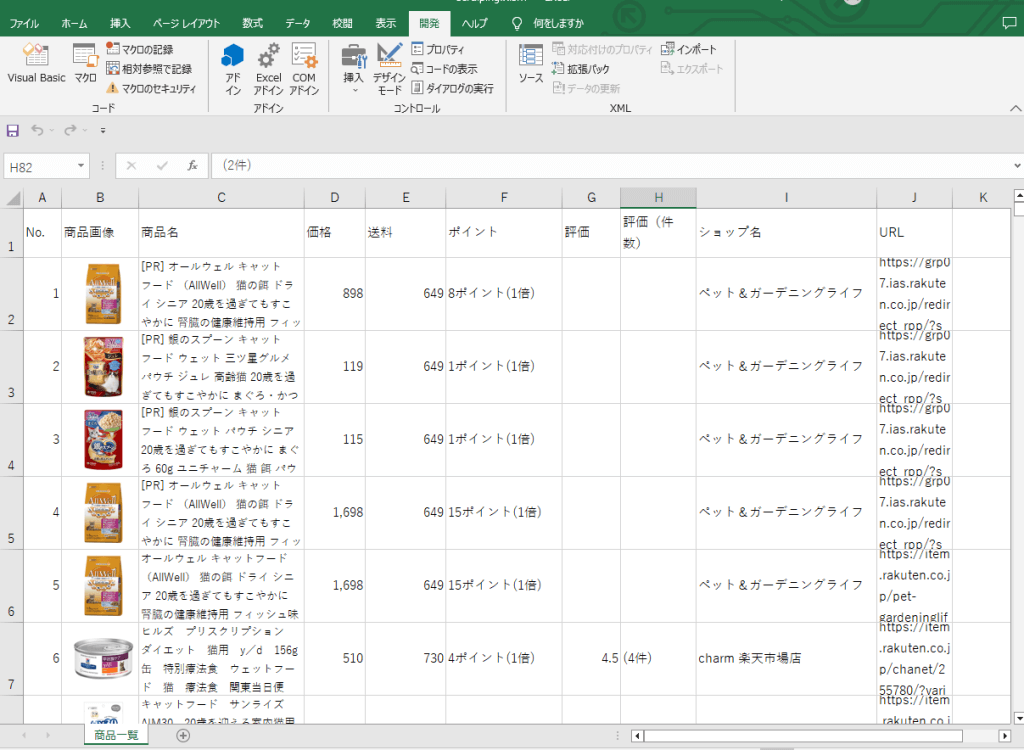
エクセルに取り込んだデータ
このような形でデータを取り込みます。ポイントは、商品情報以外にサムネイル画像も取得するところです。※キャプチャした日によって検索結果が異なっています。
取り込む際の注意事項
楽天ページを取り込む際、いくつか注意事項があります。
- 楽天のリニューアル等でHTML構造に変更があった場合、データをうまく取り込めなくなります。(最終検証:2023年3月)
- 取り込めるのは楽天の検索結果ページのみです。具体的にはURLが「https://search.rakuten.co.jp/search/mall/~」から始まるページです。
- サムネイル画像も一緒に取得するので、すべてのデータを取り込むまで時間がかかります。
- [PR]商品も一緒に取得するので、楽天の検索結果より多くの商品を取得する場合があります。
※[PR]商品とは、商品名の冒頭に[PR]がついている商品のことです。
chatGPTにIEを使わないでウェブデータを取得する方法を聞く
取得したいデータ(商品名や価格など)を内包している親要素のクラス名は「searchresultitem」です。前回のVBAコードでは「searchresultitem」を取得する際にIEを起動していました。
今回、IEを使わないでデータを取得するVBAコードをchatGPTに聞いてみます!
楽天の検索キーワードは「猫 餌 20歳」。検索結果のURLはこちらです。
https://search.rakuten.co.jp/search/mall/%E7%8C%AB+%E9%A4%8C+20%E6%AD%B3/
このウェブページからVBAで価格を取得するコードを書いてください
https://search.rakuten.co.jp/search/mall/%E7%8C%AB+%E9%A4%8C+20%E6%AD%B3/
chatGPTの回答はこちら
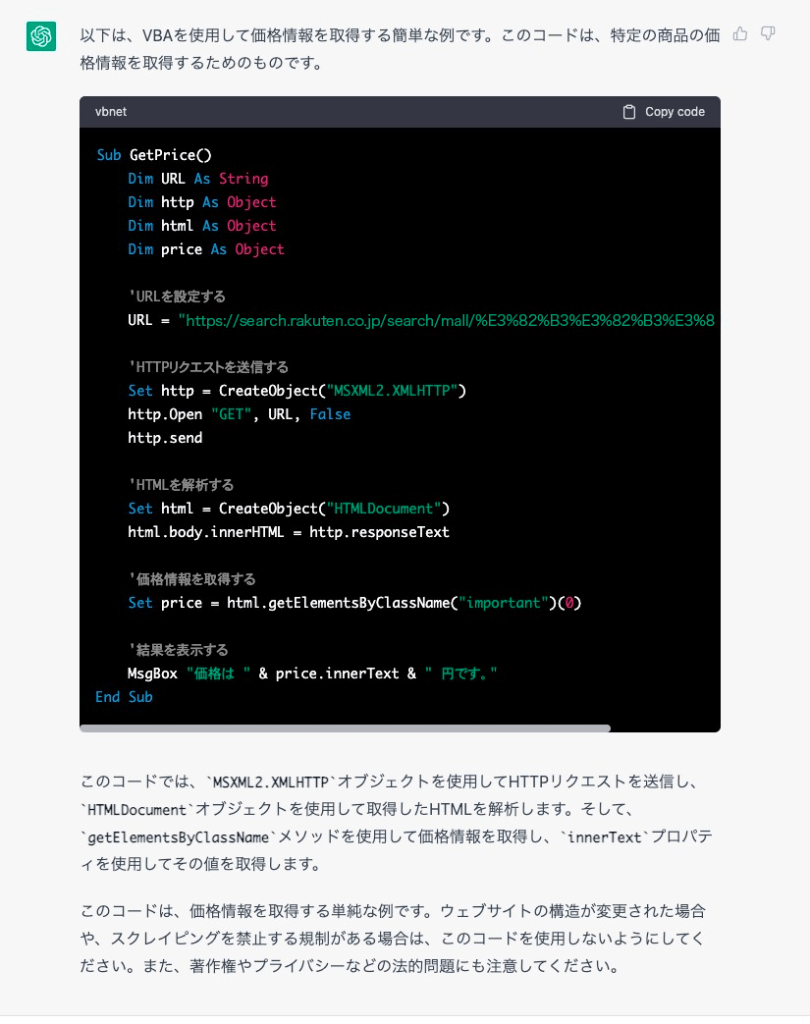
あやふやな日本語なのに、ちゃんとIEを使わずに要素を取得できるコードを書いてくれました。すごい!!残念ながらこのコードをそのまま実行しても価格は取得できませんでしたが、HTMLデータについてはコードを少し修正したら取得できました。
コードのみならず、スクレイピングを使用する際の注意点も教えてくれます。
適切に使う事が大事ですね、、、。今回のコードもVBAを理解するための勉強の成果物となります。
スクレイピングを禁止する規制がある場合は、このコードを使用しないようにしてください。また、著作権やプライバシーなどの法的問題にも注意してください。
Introducing ChatGPT – OpenAI
ウェブからデータを取得する方法がわかったので、これを前回のコードに当てはめていけば良さそうです。
あと、楽天のCSSのクラス名が変更になっていました。具体的には価格と送料、ポイントのクラス名です。2020年の時より、クラス名は長くなり細分化されていました。
商品のHTMLに設定されているクラス名は次のようになっています。
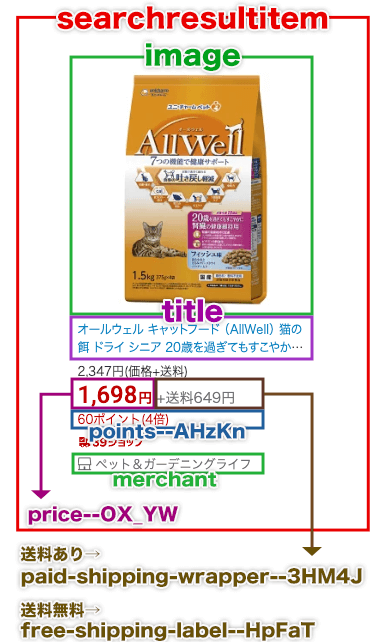
これらを踏まえて、コードを書き直します。
完成したコード
こちらが完成したコードです。
相変わらず怪しいコードですが、完成したのでメモしておきます!
Option Explicit
'URLを指定してデータを取得する
Function getDoc(UrlTarget As String) As Object
Dim xmlHttp As Object
Dim htmlDoc As Object
'XMLHTTPオブジェクトを作成してHTMLを取得
Set xmlHttp = CreateObject("MSXML2.XMLHTTP")
xmlHttp.Open "GET", UrlTarget, False
xmlHttp.send
'ページが完全に表示されるまで待機
Do While xmlHttp.readyState < 4
DoEvents
Loop
'HTMLドキュメントを作成して解析
Set htmlDoc = CreateObject("htmlfile")
htmlDoc.body.innerHTML = xmlHttp.responseText
Set getDoc = htmlDoc
End Function
Sub DownloadItems_Make()
'一覧取得
Dim i As Long
Dim rowNum As Long
Dim FirstrowNum As Long
Dim getItemNum As Long
Dim shp As Shape
Dim elmItem As Object
Dim divElm As Object
Dim tagElm As Object
Dim itemName As String
Dim itemImage As String
Dim itemPrice As String
Dim itemShipping As String
Dim itemPoint As String
Dim itemShopName As String
Dim itemURL As String
Dim itemScore As String
Dim itemLegend As String
Dim prCount As Long
Dim reg As Object
Set reg = CreateObject("VBScript.RegExp")
Dim LastNum As Long
Dim FirstNum As Long
Dim allItemNum As Long
Dim confirmBox As Variant
LastNum = 0
FirstNum = 1
FirstrowNum = 2
rowNum = FirstrowNum
getItemNum = 0
prCount = 0
getAllItemFlag = False
Sheets("商品一覧").Select
'データをクリアする
Cells.ClearContents
For Each shp In ActiveSheet.Shapes
If shp.Type = msoLinkedPicture Then
shp.Delete
End If
Next
'タイトル入力
Cells(1, 1) = "No."
Cells(1, 2) = "商品画像"
Cells(1, 3) = "商品名"
Cells(1, 4) = "価格"
Cells(1, 5) = "送料"
Cells(1, 6) = "ポイント"
Cells(1, 7) = "評価"
Cells(1, 8) = "評価(件数)"
Cells(1, 9) = "ショップ名"
Cells(1, 10) = "URL"
'幅指定
Cells(1, 1).ColumnWidth = 5
Cells(1, 2).ColumnWidth = 10.75
Cells(1, 3).ColumnWidth = 23.75
Cells(1, 4).ColumnWidth = 8.38
Cells(1, 5).ColumnWidth = 11.25
Cells(1, 6).ColumnWidth = 16.5
Cells(1, 7).ColumnWidth = 8
Cells(1, 8).ColumnWidth = 10.5
Cells(1, 9).ColumnWidth = 26
Cells(1, 10).ColumnWidth = 10.5
Dim htmlDoc As Object
Dim elements As Object
Dim element As Object
Dim url As String
'対象URLを設定
url = "https://search.rakuten.co.jp/search/mall/%E7%8C%AB+%E9%A4%8C+20%E6%AD%B3/"
'URLを指定してデータを取得する
Set htmlDoc = getDoc(url)
'対象ページの判定
If htmlDoc.getElementsByTagName("html").Length = 0 Then
MsgBox "ページ情報が取得できませんでした。URLを確認してください。"
Exit Sub
End If
If htmlDoc.getElementsByClassName("searchresultitem").Length = 0 Then
MsgBox "対象ページではありません。処理を中止します。"
Exit Sub
End If
'正規表現 トータル数から「件」を削除
With reg
.Pattern = ".*?\((.+)件\)"
.IgnoreCase = False
.Global = True
End With
'検索結果トータル数
allItemNum = reg.Replace(htmlDoc.getElementsByClassName("_medium")(0).innerText, "$1")
'メッセージボックス表示
confirmBox = InputBox("楽天の検索結果は" & Format(allItemNum, "#,##0") & "件(PR商品含まない)でした。" & vbNewLine & "取得する商品の数を入力してください。 " & vbNewLine & "何も入力しない場合、全ての検索結果を取得します。" & vbNewLine & vbNewLine & "(注)PCの処理が重くなるので、取得数は2,000件以内がおすすめです。")
'メッセージボックスをキャンセルした時の処理
If StrPtr(confirmBox) = 0 Then
MsgBox "キャンセルされたので処理を中止します。"
Exit Sub
End If
'実行条件の設定
If confirmBox = "" Then
getItemNum = 0
MsgBox "全ての商品を取得します。"
ElseIf IsNumeric(confirmBox) Then
If Int(confirmBox) >= 1 Then
getItemNum = confirmBox
Else
MsgBox "取得する数は1以上を入力してください。処理を中止します。"
Exit Sub
End If
Else
MsgBox "数字以外の文字が入力されました。処理を中止します。"
Exit Sub
End If
Start:
Cells(rowNum, 1).Select
Set elmItem = htmlDoc.getElementsByClassName("searchresultitem")
'HTML要素取得
For Each divElm In elmItem
If getItemNum > 0 And rowNum >= getItemNum + FirstrowNum Then
Exit For
End If
On Error Resume Next 'エラーが発生しても処理を継続
For Each tagElm In divElm.Children
'画像のURLを取得
If tagElm.className Like "*image*" Then
itemImage = tagElm.getElementsByClassName("_verticallyaligned")(0).src
End If
'商品名/商品URL取得
If tagElm.className Like "*title*" Then
itemName = tagElm.getElementsByTagName("h2")(0).innerText
itemURL = tagElm.getElementsByTagName("a")(0).href
If InStr(itemName, "[PR]") > 0 Then
prCount = prCount + 1
End If
End If
'価格取得
itemPrice = tagElm.getElementsByClassName("price--OX_YW")(0).innerText
'価格の「円」を削除
With reg
.Pattern = "円"
.IgnoreCase = False
.Global = True
End With
itemPrice = reg.Replace(itemPrice, "")
'送料取得
itemShipping = tagElm.getElementsByClassName("paid-shipping-wrapper--3HM4J")(0).innerText
With reg
.Pattern = "\+送料(.+)円"
.IgnoreCase = False
.Global = True
End With
itemShipping = reg.Replace(itemShipping, "$1")
If itemShipping = "" Then
itemShipping = tagElm.getElementsByClassName("free-shipping-label--HpFaT")(0).innerHTML
End If
'ポイント取得
itemPoint = tagElm.getElementsByClassName("points--AHzKn")(0).innerText
'ショップ名取得
If tagElm.className Like "*merchant*" Then
itemShopName = tagElm.getElementsByTagName("a")(0).innerText
End If
'レビュー取得
If tagElm.className Like "*review*" Then
itemScore = tagElm.getElementsByClassName("score")(0).innerText
itemLegend = tagElm.getElementsByClassName("legend")(0).innerText
End If
Next tagElm
'セルにデータを反映
Cells(rowNum, 1) = rowNum - 1
' Cells(rowNum, 2) = itemImage
Cells(rowNum, 3) = itemName
Cells(rowNum, 4) = itemPrice
Cells(rowNum, 5) = itemShipping
Cells(rowNum, 6) = itemPoint
Cells(rowNum, 7) = itemScore
Cells(rowNum, 8) = itemLegend
Cells(rowNum, 9) = itemShopName
Cells(rowNum, 10) = itemURL
' 画像を取得して貼り付ける
InsertImage itemImage, rowNum
rowNum = rowNum + 1 'セルを一行進める
Next divElm
'複数ページあるかチェック
If (htmlDoc.getElementsByClassName("dui-pagination")(0)) > 0 Then
LastNum = htmlDoc.getElementsByClassName("item -last")(0).innerText
End If
'複数ページある場合
If LastNum > FirstNum Then
FirstNum = FirstNum + 1
'全ての商品を取得
If getItemNum = 0 Then
Set htmlDoc = getDoc(url & "?p=" & FirstNum)
GoTo Start
'取得数をオーバーした場合、ページ移動をストップ
ElseIf rowNum <= getItemNum + FirstrowNum Then
Set htmlDoc = getDoc(url & "?p=" & FirstNum)
GoTo Start
End If
End If
MsgBox _
"商品一覧を作成しました。" & vbNewLine & vbNewLine & _
"取得数:" & Format(rowNum - FirstrowNum, "#,##0") & "件([PR]商品:" & prCount & "件含む)" & vbNewLine & _
"※楽天の検索結果は" & Format(allItemNum, "#,##0") & "件でした。"
End Sub
' 画像を取得
Sub InsertImage(imageURL As String, targetRow As Long)
Cells(targetRow, 2).Select
With ActiveSheet.Shapes.AddPicture( _
Filename:=imageURL, _
LinkToFile:=True, _
SaveWithDocument:=False, _
Left:=Selection.Left + 10, _
Top:=Selection.Top + 5, _
Width:=0, _
Height:=0)
.ScaleHeight 0.22, msoTrue
.ScaleWidth 0.22, msoTrue
.LockAspectRatio = True
.Width = 55
Cells(targetRow, 2).RowHeight = .Height + 10
End With
End Subこちらのコードを実行すると、商品の取得数を設定するダイアログが表示されます。
尚、コードでは「猫 餌 20歳」の検索結果を取得するように設定されているので、他の結果を取得する場合、MakeDownloadItemsプロシージャーで宣言されている変数urlの値を変更してください!
URLを設定するところ
'対象URLを設定
url = "https://search.rakuten.co.jp/search/mall/%E7%8C%AB+%E9%A4%8C+20%E6%AD%B3/" まとめ
最初はchatGPTにコードを全て書いてもらおうとしましたが、提示されたコードをコピペしても動きませんでした、、。なので、価格だけを取得するコードについて聞いてみましたが、これもコピペではうまくいかず、、。
質問方法にコツ?があるみたいです。また、動かないコードを直す技術も必要みたいです。
chatGPTは、まだまだ始まったばかりのサービスなので、数年後にはもっと進化していると思います。その際に改めて同じ質問をしたいと思います!

